
Read in english: How to save PDF book from Archive.org
Per ricercatori, studenti e amanti dei libri, Archive.org e OpenLibrary.org sono sorgenti immense di libri digitali gratuiti. Tuttavia, una limitazione è sempre stata l’impossibilità di scaricare facilmente le anteprime dei libri per la consultazione offline. È qui che entra in gioco l’estensione Chrome “Book to PDF Downloader da Archive.org”.
Questo potente strumento consente agli utenti di convertire le anteprime dei libri in PDF scaricabili, semplificando lo studio, l’annotazione e l’archiviazione di testi digitali. Che tu stia lavorando a un articolo accademico, conservando libri rari o semplicemente leggendo offline, questa estensione risolve un problema critico nell’accesso ai libri digitali.
Puoi installare questa estensione dalla pagina ufficiale del Chrome Web Store al seguente link:
https://chromewebstore.google.com/detail/archiveorg-flipbook-to-pd/egdopahkemfhieboaplafiabdfejfeip
Perché è stata creata questa estensione
Molti utenti di Archive.org e OpenLibrary.org hanno riscontrato la stessa frustrazione: le anteprime sono disponibili solo nel browser e non esiste un modo integrato per salvarle come un singolo documento. Mentre alcuni libri possono essere presi in prestito come PDF o EPUB, molti sono disponibili solo come anteprime con accesso limitato alle pagine.
Creare manualmente uno screenshot di ogni pagina è noioso e gli strumenti esistenti spesso falliscono con le immagini basate su blob (un formato comune utilizzato da queste piattaforme). Questa estensione è stata progettata per:
- Automatizzare il processo di estrazione
- Gestire gli URL dei blob senza problemi
- Compilare le pagine in un unico PDF
- Preservare la qualità delle immagini
Come funziona
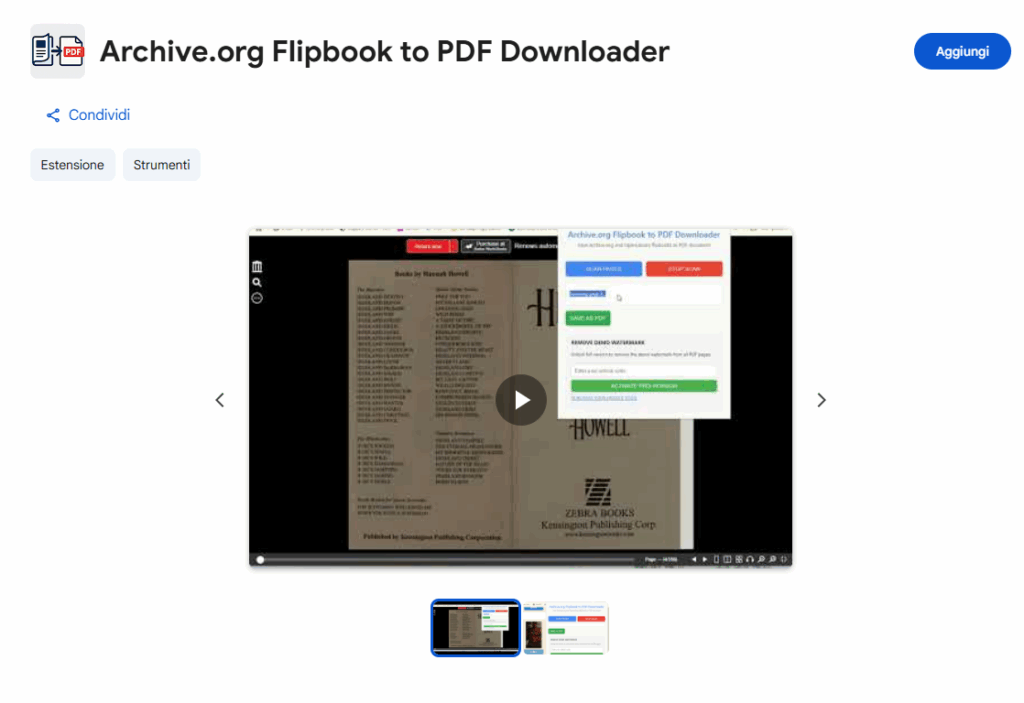
1. Scansione automatica delle pagine
Una volta attivata, l’estensione:
- Rileva tutte le pagine di anteprima disponibili (incluse quelle caricate dinamicamente).
- Scorre automaticamente, catturando ogni pagina senza intervento manuale.
- Salta i duplicati, garantendo un output pulito e perfetto.
2. Supporto URL BLOB
A differenza di altri strumenti che non riescono a gestire gli URL BLOB (blob:https://archive.org/…), questa estensione li converte in immagini leggibili utilizzando l’API Canvas, garantendo che nessuna pagina venga tralasciata.
3. Generazione PDF
Dopo la scansione, l’estensione:
- Combina tutte le immagini in un unico PDF.
- Ottimizza le dimensioni del file senza sacrificare la leggibilità.
- Fornisce un download con un clic.
Chi dovrebbe usare questa estensione?
1. Ricercatori e accademici
Salva le anteprime dei libri per annotazioni e citazioni.
Crea biblioteche di riferimento offline per progetti a lungo termine.
2. Studenti
Estrarre anteprime di libri di testo per i materiali di studio.
Evitare di dipendere da un accesso costante a Internet.
3. Archivisti e appassionati di libri
Conservare libri rari o fuori catalogo in formato PDF.
Creare biblioteche digitali personali.
4. Lettori occasionali
Leggere libri offline senza dover catturare manualmente le pagine.
Memorizzare le anteprime prima che diventino non disponibili.
Confronto con altre alternative
| Funzionalità | Questa Estensione | Screenshot Manuali | Altri Downloaders |
|---|---|---|---|
| Auto-Scroll & Cattura immagini | ✅ Si | ❌ No | ❌ Alcuni |
| Gestisce Blob URLs |
✅ Si | ❌ No | ❌ Falliscono spesso |
| Rimuove duplicati | ✅ Si | ❌ No | ⚠️ A volte |
| One-Click PDF Export | ✅ Si | ❌ No | ✅ Alcuni |
| Funziona su Archive.org/OpenLibrary | ✅ Si | ✅ Si | ❌ Non funzionano |
Perché questa estensione è migliore:
- Nessun lavoro manuale – Completamente automatizzato.
- Nessuna pagina mancante – Gestisce il caricamento dinamico e gli URL BLOB.
- Output PDF pulito – Nessun duplicato o problema di formattazione.
Considerazioni etiche
Questo strumento è progettato per un uso corretto e rispetta il copyright:
- Funziona solo su anteprime disponibili al pubblico (non su libri presi in prestito/con restrizioni).
- Non aggira i paywall o i limiti di prestito.
- Ideale per la ricerca, non per la pirateria.
- Gli utenti dovrebbero sempre verificare lo stato del copyright prima di ridistribuire i contenuti scaricati.
Come installare e usare
Installazione
-
Scarica e installa dal Chrome Web Store (clicca sull’immagine sottostante)
2. Utilizzo
- Apri l’anteprima del libro su Archive.org o OpenLibrary.org.
- Clicca sull’icona dell’estensione.
- Avvia la scansione: scorrerà automaticamente e catturerà le pagine.
- Scarica il PDF al termine premendo su Download PDF


GloboSoft è una software house italiana che progetta e sviluppa software per la gestione dei file multimediali, dispositivi mobili e per la comunicazione digitale su diverse piattaforme.
Da oltre 10 anni il team di GloboSoft aggiorna il blog Softstore.it focalizzandosi sulla recensione dei migliori software per PC e Mac in ambito video, audio, phone manager e recupero dati.